Functional core, imperative shell
Diario del capitán, fecha estelar d554.y38/AB

In the last few years, I have been playing with functional programming to learn other programming paradigms and grow as a developer. In this blog post, I will explain how I write tests and organise code inside services following the "functional core, imperative shell" pattern.
The two most important features of functional programming are function purity and immutable states. I'm going to focus on the first one, this time.
A function is pure when:
The former restriction, for instance, prevents the usage of things like random numbers while the latter prevents the usage of things like... databases! 😱 Some programming languages - Haskell and Elm, for example - are 100% pure, meaning that only pure functions can be written.
How on Earth can we write a program like a backend API, for example, without using a database? The solution is simpler than you might think. Read on!
First, we will need to write functions returning a data structure - sometimes called commands - describing what the database needs to do. For example, something like:
{ type: 'INSERT', table: 'posts', row: { title: '...', ... } }
This data structure is then converted into actual database calls. Because the function just returns a data structure, instead of changing the world outside, the function is pure.
The other side, to know what has changed, we accept events from the database (or any other service). For example:
{ type: 'INSERTED', table: 'posts', changes: { ... } }
With commands and events we still can observe or modify the outside world while maintaining the function purity. In other words, we separate the operations from the side effects.
You can think this is cheating: instead of storing it into the database, we specify what we need to store. Ok, I'll give you that. It feels indeed like cheating, but the code you get has two direct benefits:
We don't do Haskell at MarsBased (although I'd like to get started with Elm). How does all of this fit with our current model and tech techstack?
The idea remains the same: we need to always isolate side effects from operations.
I have written a simple fictional example for you:
def do_something(id, url, user, values)
template = Template.find(id)
page = ApiService.find(url)
content = do_something_complex_with(values, template)
if (content.conditions) CacheService.cache(page.url, content)
value = make_something_complex_with_page(user, values, page)
ApiService.update(page)
value
end
Traditionally, to unit test this code, we inject mocks ApiService and CacheService dependencies.
However, Functional Programming proposes to extract the pure parts of the code outside and unit test only those parts. Something like this:
def do_something(id, url, user, values)
template = Template.find(id)
page = ApiService.find(url)
[data, cache] = PureService.do_something_complex(values, template)
if (cache) CacheService.cache(cache.url, cache.content)
[value, update] = PureService2.do_something_complex(user, values, page)
if (update) ApiService.update(update.content)
value
end
It is expected for complex logic methods to return two things: the actual computed value and the effects (the data describing the changes) that need to be applied.
This pattern is sometimes called functional core, imperative shell:
For example, the video included in the previous link shows the test of a class named TweetRenderer. Despite the name, it doesn't render anything. It just returns an object describing what to render:
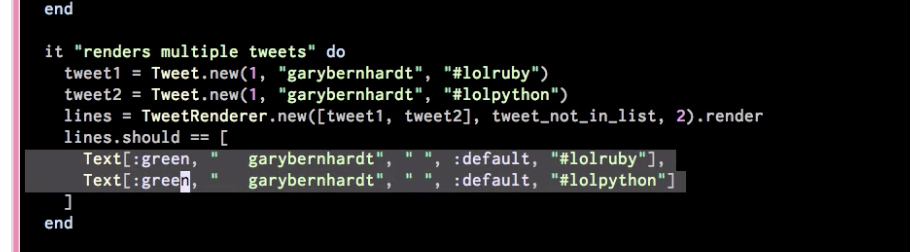
TweetRenderer spec at destroyallsoftware.com example ☝🏻
This is part of the functional core. The result of that core should be trivial to translate into actual environment changes.
There's another advantage of using commands, instead of making changes directly: commands can be (post)processed.
For example, we could return a list of database changes and some middleware code could transform that into API cache calls. The business logic is still the same but the effects are different.
Another popular example is React components. They produce a description of the DOM that is diffed against the actual DOM to produce descriptions of DOM changes. Other systems use scheduling (fibers) to apply those changes more effectively.
By separating what we should do from the actual action, the code becomes clean, and easy to understand and reason about. This pattern provides a good alternative when we want to split complex code and, at the same time, improve its testability.

Some tips on improving self-confidence when developing software projects. Being self-confident helps you writing better code and focusing on what really matters.
Leer el artículo
In this post, we explain how the reduce function works and how it can make your development easier, as it is available in all modern programming languages.
Leer el artículo
How many times have you - as an agency or freelancer - inherited code from a previous provider or another team? How many times have you been blamed for things that were not your fault? You can avoid it, if you follow our advice.
Leer el artículo